Terraform 💻

Linting
The team uses TFLint for automated code checks.
Formatting
- Always use terraform fmt to rewrite Terraform configuration files to a canonical format and style.
Naming
- Use
snake_casein all: resource names, data source names, variable names, outputs. - Only use
lowercase letters and numbers. - Always use
singular nounfor names. - Always use
double quotes.
Resource and data source arguments
-
Do not repeat the resource type in the resource name (not partially, nor completely)
resource "aws_route_table" "public" {}resource "aws_route_table" "public_route_table" {}resource "aws_route_table" "public_aws_route_table" {} -
Resource name should be named
thisif there is not a more descriptive and general name available, or if the resource module creates a single resource of this type (e.g., there is a single resource of typeaws_nat_gatewayand multiple resources of typeaws_route_table, soaws_nat_gatewayshould be namedthisandaws_route_tableshould have more descriptive names - likeprivate,public,database). Normally, the team usesthisto delegate theoutputof amoduleto theresourceitself.# modules/nimble_alb/main.tf resource "aws_lb" "nimble" { name = var.load_balancer_name load_balancer_type = "application" security_groups = [var.vpc_security_group_ids] subnets = [var.subnets] } # modules/nimble_alb/outputs.tf output "this_dns" { description = "Nimble Application load balancer DNS" value = aws_lb.nimble.dns } # main.tf module "nimble_alb" { source = "./modules/nimble_alb" #... } # Get the DNS by `module.nimble_alb.this_dns` -
Include
tagsargument, if supported by resource as the last real argument, following bydepends_onandlifecycle, if necessary. All of these should be separated by a single empty line.resource "aws_nat_gateway" "nimble" { count = "1" allocation_id = "..." subnet_id = "..." tags = { Name = "..." } depends_on = ["aws_internet_gateway.this"] lifecycle { create_before_destroy = true } } -
Add
countas the first argument at the top of each resource block, separated from the other arguments by a newline.resource "aws_route_table" "public" { count = 2 vpc_id = "vpc-12345678" #... } -
When using
countto create the resource conditionally, use abooleanvalue if it is appropriate. Otherwise, use thelengthmethod.# create_public_subnets: true resource "aws_subnet" "public" { count = var.create_public_subnets #... }or
resource "aws_subnet" "public" { count = length(var.public_subnets) > 0 ? 1 : 0 #... } -
To make inverted conditions, use
1 - {boolean value}.# create_public_subnets: true # 1 - true => false count = 1 - var.create_public_subnets
Variables
- Do not reinvent the wheel in resource modules - use the same variable names, description, and default as defined in the “Argument Reference” section (example) for the resource in use.
- Omit
type = "string"declaration if there isdefault = ""also - Omit
type = "list"declaration if there isdefault = []also. - Omit
type = "map"declaration if there isdefault = {}also. - Use plural form in name of variables of type
listandmap. - When defining variables order the keys:
description,type,default.
Outputs
Name for the outputs is important to make them consistent and understandable outside of its scope (when the user is using a module it should be obvious what type and attribute of the value is returned).
-
The names of outputs should be descriptive and reflect the value they contain, avoid using vague or ambiguous names.
output "alb_log_bucket_name" { description = "S3 bucket name for ALB logging" value = aws_s3_bucket.alb_log.bucket }output "alb_s3" { description = "S3 for ALB" value = aws_s3_bucket.alb_log.bucket } - Always include description on all outputs even if they are obvious.
-
If the output is returning a value with interpolation functions and multiple resources, the
{name}and{type}there should be as generic as possible (this is often the most generic and should be preferred).output "this_security_group_id" { description = "The ID of the security group" value = element(concat(coalescelist(aws_security_group.this.*.id, aws_security_group.this_name_prefix.*.id), list("")), 0) }output "security_group_id" { description = "The ID of the security group" value = element(concat(coalescelist(aws_security_group.this.*.id, aws_security_group.web.*.id), list("")), 0) } output "another_security_group_id" { description = "The ID of web security group" value = element(concat(aws_security_group.web.*.id, list("")), 0) } -
Use the plural form for the name if the returned value is a list.
output "this_rds_cluster_instance_endpoints" { description = "A list of all cluster instance endpoints" value = [aws_rds_cluster_instance.this.*.endpoint] }
Project Structure
A typical project for a cloud provider should follow this structure::
terraform-project
├── README.md
├── modules
│ ├── module_1
│ │ ├── locals.tf
│ │ ├── main.tf
│ │ ├── outputs.tf
│ │ └── variables.tf
│ └── module_2
│ ├── locals.tf
│ ├── main.tf
│ ├── outputs.tf
│ └── variables.tf
├── core
│ ├── locals.tf
│ ├── main.tf
│ ├── outputs.tf
│ ├── providers.tf
│ └── variables.tf
└── shared
├── locals.tf
├── main.tf
├── outputs.tf.
├── providers.tf
└── variables.tf
The project is organized into 3 directories:
-
modules: contains shared modules, where each module is a collection of connected resources that together perform a common action. For example,aws_vpccreates VPC, subnets, NAT, etc. -
shared: uses the shared modules defined under/modulesto create shared resources for all environments, e.g. AWS ECR, IAM groups and users. These resources must be created first before creating any environment-specific resources. -
core: uses the shared modules defined under/modulesto create resources for each environment, e.g. staging DB cluster, production DB cluster.
Each directory share the same file structure
-
main.tf: use the shared Terraform modules or resources in combination with the variables and local values to create the infrastructure resources.- The
main.tffiles under/modulestypically use public modules or resources (example) from the Terraform registry. - The
main.tffiles under/coreor/sharedconsumes the modules defined under/modules.
- The
-
locals.tf: contains declarations of local values used inmain.tfwhich are the same between environments, e.g. database engine. -
variables.tf: contains declarations of variables used inmain.tfwhich can be different by each environment. -
outputs.tf: contains outputs from the resources created inmain.tf.
Under the core and shared directories, there is an additional providers.tf file that stores the configuration for the providers used in the project, such as Terraform, AWS, GCP, etc.
Main File Structure
Follow the below structure to organize the code in main.tf files.
-
Group each component in the main file together:
# data source arguments # resource/module # resource `null_resource` -
Order by
toptodownin term of execution# Create VPC first resource "aws_vpc" "nimble" {} # Create IAM role before the EC2 instance resource "aws_iam_role" "nimble_web" {} # Create EC2 instance resource "aws_instance" "nimble_web" {}
Variables vs Local Values
👉 Use local values to:
- Store setting values that do not change between application environments, such as the database engine.
- Store application configuration values by environment (
./core/locals.tf). Changes to these values should be made through code and require code review.
👉 Use variables to store setting values that may change depending on the application environment, such as the database instance type. The values of the variables will be provided or overridden (if there is a default value) by the consumer of the modules, i.e., when calling the module from /core or /share.
Typically, variables are used when defining shared modules (under /modules). This allows each application to define custom setting values when using those modules to create infrastructure resources.
Here is a simple demonstration of how to use local values and variables.
# .
# ├── modules
# │ └── rds
# │ ├── locals.tf
# │ ├── main.tf
# │ └── variables.tf
# └── core
# ├── locals.tf
# ├── main.tf
# └── variables.tf
# ./modules/rds/locals.tf
locals {
db_engine = "aurora-postgresql"
}
# ./modules/rds/variables.tf
variable "instance_class" {
description = "The Aurora DB instance class"
type = string
}
# ./module/rds/main.tf
module "db" {
source = "terraform-aws-modules/rds-aurora/aws"
engine = local.db_engine
instance_class = var.instance_class
#...
}
# ./base/variables.tf
variable "environment" {
description = "Application environment"
type = string
}
# ./base/locals.tf
locals {
current_db_config = local.db_config[var.environment]
db_config = {
staging = {
instance_class = "db.t3.small"
#...
}
prod = {
instance_class = "db.t3.large"
#...
}
}
#./base/main.tf
module "db" {
source = "../modules/db"
instance_class = local.current_db_config.instance_class
#...
}
Shared Modules
-
The team prefers using shared modules published on the registry instead of individual Terraform resources to manage infrastructure resources. This approach can reduce code, improve consistency, enable reuse, and implement best practices.
module "db" { source = "terraform-aws-modules/rds-aurora/aws" version = "7.6.0" name = local.cluster_id engine = local.engine engine_version = var.engine_version vpc_id = var.vpc_id subnets = var.subnet_ids #... }resource "aws_db_instance" "main" { #... } resource "aws_db_subnet_group" "db-subnet" { name = "db_subnet_group" subnet_ids = var.subnet_ids } -
Always set the
module versionto ensure predictability, security, and stability and avoid breaking changes.module "rds" { source = "terraform-aws-modules/rds/aws" version = "2.18.0" #... }module "rds" { source = "terraform-aws-modules/rds/aws" #... }
Resource Tagging
Use the default_tags under Terraform provider to ensure that there are at least two default tags: environment and owner, to group all created resources by the project and its environment. These tags are useful to group all project resources (e.g. to filter on billing dashboard), in case there are other resources created by other teams or projects.
# ./shared/provider.tf
provider "aws" {
region = local.region
default_tags {
tags = {
Environment = var.environment # staging
Owner = local.owner # ACME
}
}
}
State Storage
Always using Remote State
-
Start the project with Terraform Cloud Remote State Management if it is possible.
terraform { cloud { organization = "nimble" workspaces { name = "overblock" } } } -
Storing Terraform states in a remote bucket, such as AWS S3, is recommended as a second option.
terraform { backend "s3" { region = "aws_region" # This bucket needs to be created beforehand bucket = "bucket_name" key = "aws-setup/state.tfstate" encrypt = true # AES-256 encryption } }
Security
-
Do NOT skip an entire check of the scanning tool. Instead, disable the check for lines of code that require an exception.
# .checkov.yaml skip-check: - CKV_AWS_20# module/s3/main.tf resource "aws_s3_bucket" "foo-bucket" { region = var.region bucket = local.bucket_name force_destroy = true #checkov:skip=CKV_AWS_20:The bucket is a public static content host acl = "public-read" } - Avoid hardcoding sensitive data such as passwords or SSH keys in Terraform code. Instead, use Terraform cloud variables to store these values and consume these values in the code.
# variables.tf # the value will be stored using a Terraform Cloud sensitive variable. variable "db_master_password" { type = string sensitive = true } # main.tf module "db" { source = "terraform-aws-modules/rds-aurora/aws" version = "7.6.0" master_password = var.db_master_password #... }
Branching Strategy
A Terraform project follows the regular branch management with two default branches: develop and main.
Each branch, in combination with a Terraform workspace, maps to an infrastructure environment.
- The
developbranch is for thestagingenvironment. - The
mainbranch is for theproductionenvironment.
Continuous Integration
While multiple services are available for Continuous Integration in a Terraform project, the team typically uses Terraform Cloud and follows the following conventions.
Workspaces Structure
An infrastructure project typically includes the following workspaces:
- A
<project-name>-sharedworkspace (e.g.acme-shared) is responsible for managing shared resources such as ECR and IAM users & groups.- Uses the
./shareddirectory as the working directory. - Map to the
developbranch.
- Uses the
- Each
<project-name>-<environment>workspace (e.g.acme-staging,acme-production) corresponds to a specific infrastructure environment.- Uses the
./coredirectory as the working directory. - Map to the
developbranch for thestagingworkspace and themainbranch for theproductionworkspace.
- Uses the
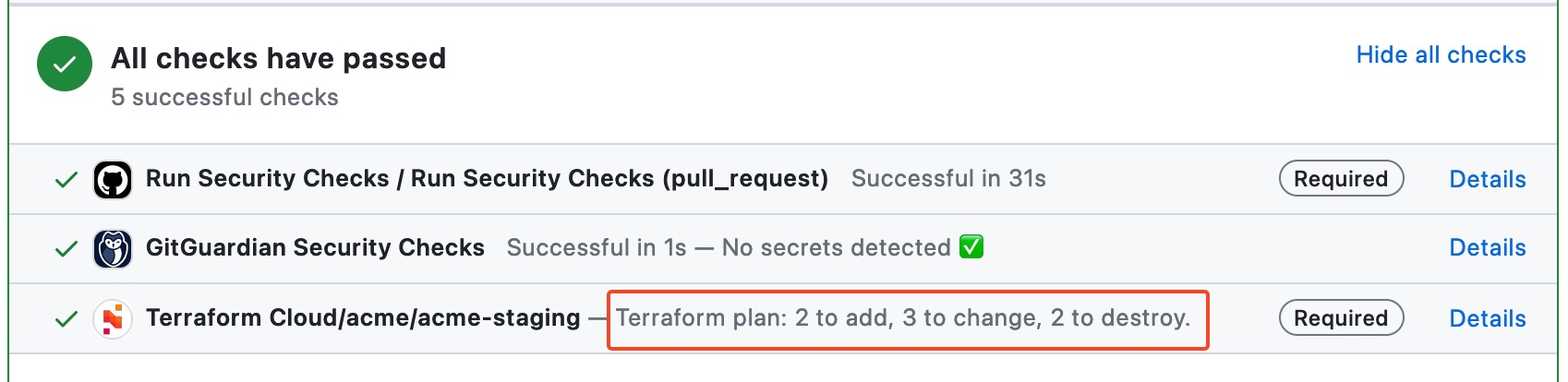
Terraform Runs
-
To avoid potential side effects, do not keep a Terraform Cloud plan for an extended period before applying as the plan could become outdated. Instead, if it is unable to apply the plan immediately after planning, initialize a new plan and apply it instead.
# In this example, the Terraform plan may become outdated # as the task definition is changed during an application deployment. data "aws_ecs_task_definition" "latest" { task_definition = "acme-web-service" }