Version Control

Git is always used for code version control. No matter how big or small the project is, Git is required at all times. While it allows to track changes and revert them far beyond what ctrl-z could do 😨, it is also a powerful tool for team collaboration.
Services
Unless the client requests another service, use GitHub to host the code for all kinds of projects.
Repositories can be public or private:
- Use private repositories for closed source or clients’ projects.
- Use public repositories for open source projects developed by Nimble.
Tools
No specific tool is enforced at the team level to use Git on a local machine. The following tools are the ones most commonly used.
Terminal
The built-in terminal in macOS or the powerful iTerm2 replacement terminal.
The terminal experience can be greatly enhanced when used in combination with GitHub CLI.
Built-in Tool in IDEs
Whether using Visual Studio Code or one of the JetBrain’s IDE — the most in use being RubyMine, GoLand, and Android Studio — all IDEs come with a built-in panel to interact visually with Git.
Standalone Applications
GitHub Desktop and Sourcetree provide similar benefits as the built-in Git tool in IDEs in interacting visually with Git but, as a standalone and focused application, they also come with more advanced functionalities.
These tools, while targeted at developers, are also well-suited for non-technical team members as it removes the need to learn Git commands.
Template
When starting a new project, use one of the custom and maintained template repositories for each stack:
- Android: github.com/nimblehq/android-templates
- Dart/Flutter github.com/nimblehq/flutter_templates
- Elixir/Phoenix github.com/nimblehq/elixir-templates
- Go/Gin: github.com/nimblehq/gin-templates
- Infrastructure/Terraform: github.com/nimblehq/infrastructure-templates
- iOS: github.com/nimblehq/ios-templates
- React: github.com/nimblehq/react-templates
- Ruby/Rails: github.com/nimblehq/rails-templates
In the event that none of these project templates is suited, the Git project template repository must be used to initialize the project.
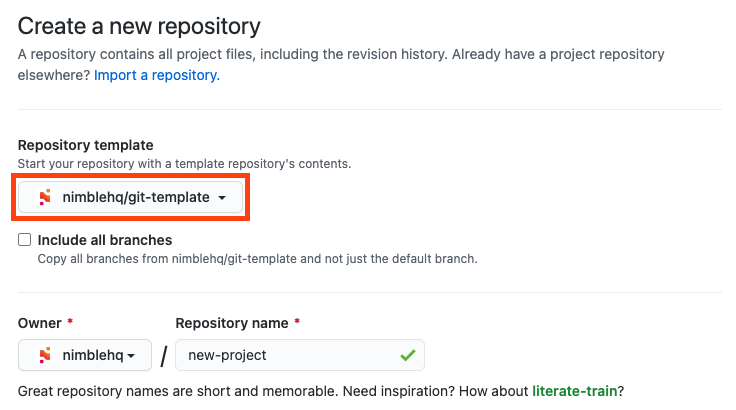
The repository comes with a standardized README, pull request, and issue templates.